Les tests statistiques sont omniprésents, de la médecine à la technologie en passant par la politique. Dans cet article, nous présentons la notion de test statistique à travers l'exemple simple du lancer d'une pièce de monnaie. Puis nous approfondissons les concepts introduits avec un autre exemple, plus applicable à la vie réelle, mais aussi plus contre-intuitif.
Test Statistique
Imaginez que vous avez acheté une pièce d'un euro truquée dans une boutique de magie. Elle est biaisée de manière que lorsqu'elle est lancée, elle tombe sur pile avec une probabilité $0.8$ et sur face avec une probabilité $0.2$. Après l'avoir achetée, vous l'avez mise machinalement dans votre sac à main oubliant qu'il s'y trouvait déjà des pièces d'un euro équilibrées ! Maintenant, vous voulez retrouver laquelle des pièces de votre sac est celle qui est truquée. Le défi pour vous, cher lecteur, est donc de concevoir une méthode pour déterminer, étant donné une pièce d'un euro de votre sac à main, si elle est truquée ou pas. Le défi pour moi, est de vous guider vers une solution.
Vous pouvez évidement lancer la pièce un grand nombre de fois et compter le nombre de piles et faces obtenus. Si la pièce est équilibrée alors on s'attend à ce que ces deux nombres soient à peu près égaux (ce résultat est connu sous le nom de loi forte des grands nombres).
Si nous modélisons le lancer de la pièce par une variable aléatoire $X$ à valeurs dans ${ 0, 1}$ (nous représentons "pile" par $1$ et "face" par $0$) alors nous cherchons à vérifier si
$$\mathbb{P}(X=1) = 0.8 , \text{ et } \mathbb{P}(X=0) = 1 - 0.8 = 0.2, (1)$$
si la pièce est truquée, ou
$$\mathbb{P}(X=1) = 0.5 , \text{ et } \mathbb{P}(X=0) = 1 - 0.5 = 0.5 (2)$$
si elle est équilibrée.
Supposons que vous faisiez $n$ lancers avec la pièce truquée et notons $X_{i}$ le résultat de l'ième lancer. La loi forte des grands nombres nous assure que quand $n$ tend vers l'infini,
$$\overline{X_n} := \frac{1}{n} \sum_{i=1}^{n}X_i \underset{n\to \infty}{\longrightarrow} \mathbb{E}[X],, \text{presque sûrement1} (3)$$
$$\text{où } \mathbb{E}[X] = 1\cdot P(X=1) + 0\cdot P(X=0) = P(X=1) = 0.8 (4)$$
Puisqu'on ne peut pas faire un nombre infini de lancers pour vérifier si la valeur de $\mathbb{P}(X=1)$ est $0.8$ ou $0.5$, il faut trouver une autre façon de répondre à notre question. Heureusement, il existe un outil mathématique fait pour nous !
La procédure est la suivante: nous fixons $t \geq 0$. Étant donné $n$ observations $x_1, x_2, ... , x_n$ respectivement, c'est-à-dire une suite de $n$ chiffres $0$ ou $1$, notons $\overline{x_n}$ leur moyenne (comme dans (3)). Si $\overline{x_n}$ est dans l'intervalle $\left[0.8 - t, 0.8 + t\right]$ alors nous décidons que la pièce est biaisée (c'est la pièce que vous avez achetée dans la boutique de magie). Si $\overline{x_{n}}$ n'est pas dans cet intervalle alors nous décidons que cette pièce est équilibrée. Bien que cette méthode soit imparfaite, elle donne un premier angle d'attaque.
Ce que nous venons de décrire est un test d'hypothèse. De manière un peu plus formelle, on définit un test d'hypothèse $H_{0}$ contre l'hypothèse $H_{1}$ comme toute fonction $\psi(X_1,...,X_n )$ à valeurs dans {0 ,1}. Lorsque $\psi(X_1,...,X_n) =0$, on conserve $H_0$ ; lorsque $\psi(X_1,...,X_n) =1$, on rejette $H_0$ et donc on accepte $H_1$.
Dans ce contexte : $$\text{On note $H_1$ l'hypothèse : la pièce est biaisée} (5)$$ $$\text{On note $H_0$ l'hypothèse : la pièce est équilibrée} (6)$$
L'hypothèse $H_0$ est appelée l'hypothèse nulle, c'est-à-dire celle qui signifie "pas d'effet" ou "ce qu'on voit pourrait être expliqué par le hasard". L'hypothèse $H_{1}$ est appelée l'hypothèse alternative, et c'est souvent l'hypothèse qu'on souhaite vérifier (en rejetant $H_{0}$).
Un exemple qui illustre bien les notions d'hypothèses nulle et alternative est celui de l'essai d'un nouveau médicament. Du point de vue du fabricant du médicament, il est naturel de prendre pour $H_1$ l'hypothèse "le médicament a une efficacité", et donc pour $H_0$ "le médicament ne fonctionne pas" ou "il ne vaut pas mieux qu'une pilule de sucre". Dans notre cas, étant donné une pièce d'un euro venant de notre sac, l'hypothèse nulle pourrait s’interpréter comme ``le comportement de cette pièce est compatible avec celui d'une pièce équilibrée" ou "ce n'est pas une pièce truquée".
Faux positifs et Faux négatifs
Pouvons nous faire confiance à notre test ? Si par exemple on prend $t \geq 0.8$, toute pièce équilibrée sera identifiée comme biaisée (faux positif). Pour $t = 0$ en revanche, notre test identifie très facilement la pièce biaisée comme équilibrée (faux négatif). Nous voudrions pouvoir décrire les proportions de faux positifs et faux négatifs pour chaque $t$ de façon à quantifier le comportement de notre test. On pourrait même vouloir choisir le "meilleur" $t$ pour optimiser notre test. Pour quantifier ces deux erreurs, introduisons deux définitions importantes.
On définit l'erreur de première espèce $\alpha$ d'un test comme la probabilité d'accepter $H_{1}$ à tort (faux positif). De même, on définit l'erreur de seconde espèce $\beta$ comme l'erreur d'accepter $H_{0}$ (donc de rejeter $H_1$) à tort (faux négatif). Nous les notons
$$\alpha(t) = \mathbb{P}^{H_0}\left(\psi_{t}(X_1,..,X_n) = 1\right) (8)$$ $$\beta(t) = \mathbb{P}^{H_1}\left(\psi_{t}(X_1,..,X_n) = 0\right) (9)$$
Remarque : On introduit généralement avec ces deux définitions les concepts de sensibilité et de spécificité. La sensibilité correspond à la probabilité d'accepter à raison $H_{1}$ (égal à $1 - \beta$) et la spécificité correspond à la probabilité d'accepter (à raison) $H_{0}$ (égal à $1 - \alpha$).
Dans notre exemple on travaille avec une loi de probabilité de Bernoulli de paramètre $p \in {0.5, 0.8}$ ; $H_1$ équivaut à $p = 0.8$, donc $X$ suit une loi de probabilité $Ber(0.8)$. De même, $H_0$ est équivalent à $X \sim Ber(0.5)$. Ainsi, par exemple, l'erreur de première espèce associée à notre test est donnée par
$$\alpha(t) = \mathbb{P}_{X \sim Ber(0.5)} \left(\overline{X_n} \in \left[0.8 - t, 0.8 + t\right] \right)$$
$$= \mathbb{P}_{X \sim Ber(0.5)} \left( \frac{1}{n}\sum_{i=1}^{n}X_{i} \in \left[0.8 - t, 0.8 + t\right] \right)$$
$$= \mathbb{P}_{X \sim Ber(0.5)}\left( \sum_{i=1}^{n}X_{i} \in \left[n(0.8 - t), n(0.8 + t) \right]\right) (10)$$
En utilisant le fait que les variables aléatoires $X_{i}$ sont indépendantes et suivent une loi de Bernoulli, (10) peut s'écrire sous la forme :
$$\alpha(t) = \mathbb{P}_{Y \sim Bin(n,0.5)} \left( Y \in \left[n(0.8 - t), n(0.8 + t)\right] \right)$$
$$= \sum_{k = \lceil n(0.8 - t) \rceil}^{ \lfloor n(0.8 + t) \rfloor}
\begin{pmatrix}
n\\
k
\end{pmatrix}
(0.5)^{k}(0.5)^{n-k}$$
$$= (0.5)^{n}\sum_{k = \lceil n(0.8 - t) \rceil}^{ \lfloor n(0.8 + t) \rfloor}
\begin{pmatrix}
n\\
k
\end{pmatrix} (11)$$
De même, on peut décrire l'erreur de second espèce
$$\beta(t) = \mathbb{P}_{X \sim Ber(0.8)} \left( \overline{X_n} \notin
\left[0.8 - t, 0.8 + t\right]\right)$$
$$= \mathbb{P}_{Y \sim Bin(n,0.8)} \left( Y \in \left[0, n(0.8 - t) \right[ \cup \left] n(0.8 + t), n\right] \right)$$
$$= \sum_{k = 0}^{\lceil n(0.8 - t) \rceil -1}
\begin{pmatrix}
n\\
k
\end{pmatrix}
(0.8)^{k}(1 - 0.8)^{n - k}
+ \sum_{k = \lfloor n(0.8 + t) \rfloor + 1}^{n}
\begin{pmatrix}
n\\
k
\end{pmatrix}
(0.8)^{k}(1 - 0.8)^{n - k}$$
$$= 0.8^{n}\left(
\sum_{k = 0}^{\lceil n(0.8 - t) \rceil -1}
\begin{pmatrix}
n\\
k
\end{pmatrix}
4^{n-k}
+ \sum_{k = \lfloor n(0.8 + t) \rfloor + 1}^{n}
\begin{pmatrix}
n\\
k
\end{pmatrix}
4^{n-k}
\right) (12)$$
Mettons maintenant en pratique ce que nous venons de construire pour tester une des pièces du sac à main. En lançant une pièce disons $n = 50$ fois, nous obtenons une suite $x_{1},x_{2},...,x_{50}$ de $0$ et de $1$. Supposons pour le moment que la pièce est équilibrée (hypothèse $H_{0}$) et prenons $t = 0.1$. Alors
$$\alpha (0.1) \sim 3.3\cdot 10^{-3} (13)$$
Supposons maintenant $H_1$, c'est-à-dire que la pièce est truquée ; la probabilité d'accepter $H_{0}$ est alors
$$\beta(0.1) \sim 4.9\cdot 10^{-2} (14)$$
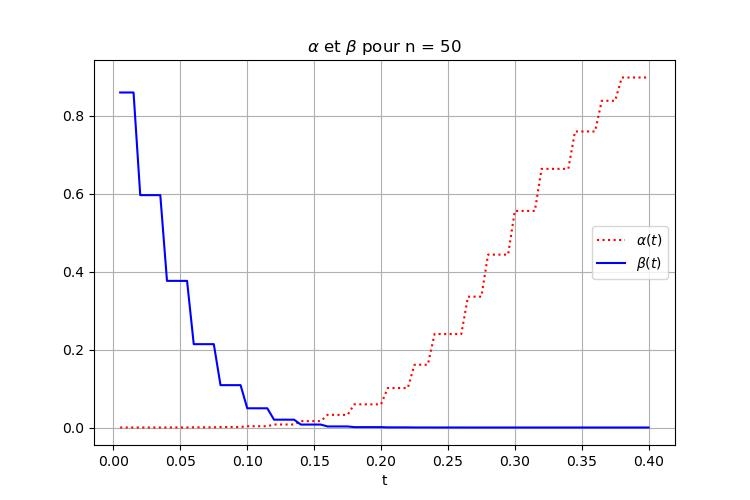
On illustre le comportement de ces deux erreurs en fonction du paramètre $t$ dans la Figure 1. Vous pouvez constater que les valeurs extrêmes du paramètre $t$ donnent des erreurs de première ou deuxième espèce très importantes. Pour $t \in [0.1,0.2]$ les deux erreurs sont plus petites que $6\cdot10^{-2}$.
Peut-on conclure que notre test est assez bon ? Tâchons de répondre à cette question avec un exemple. Supposons que dans votre sac à main il y a 4 pièces d'un euro équilibrées (hypothèse réaliste) : cela signifie qu'une pièce sur cinq est la pièce truquée. Si nous prenons une de ces pièces au hasard pour la tester alors
$$\mathbb{P}^{H_0}\left(\psi_{0.1}\left(X_1, \ldots X_n\right) = 1\right) = \mathbb{P}\left( \psi_{0.1}\left(X_{1},\ldots,X_{n}\right)=1 | H_{0} \right)$$ $$\mathbb{P}^{H_1}\left(\psi_{0.1}(X_1,..,X_n) = 0\right) = \mathbb{P}\left(\psi_{0.1}(X_1,\ldots,X_n) = 0 | H_{1}\right).$$
Appliquons maintenant notre test. Après $50$ lancers... le résultat est $\psi = 1$! Quelle est la probabilité d'avoir raison si nous considérons que la pièce que nous avons prise est truquée sachant que notre test l'identifie comme biaisée ? Un petit calcul nous montre que cette probabilité est
$$\mathbb{P}(H_{1}|\psi_{0.1} = 1) = \frac{\mathbb{P}(\psi_{0.1} =1 | H_{1}) \mathbb{P}(H_{1})}{\mathbb{P}(\psi_{0.1}=1)} , \text{ (Théorème de Bayes) }$$ $$= \frac{ (1 - \mathbb{P}(\psi_{0.1}=0|H_{1}) ) \mathbb{P}(H_{1}) }{ \mathbb{P}(\psi_{0.1}=1) }$$ $$= \frac{ (1 - \beta(0.1)) 0.2 }{ \mathbb{P}(\psi_{0.1}=1|H_{0}) \mathbb{P}(H_{0}) + \mathbb{P}(\psi_{0.1}=1|H_{1})\mathbb{P}(H_{1}) }$$ $$= \frac{ (1 - \beta(0.1)) 0.2 }{ \alpha(0.1) \cdot 0.8 + (1 - \beta(0.1)) 0.2}$$ $$\sim 0.9863\ldots (15)$$
Ce n'est pas loin d'être parfait ! De même, nous pouvons calculer la probabilité d'avoir raison en ignorant une pièce pour laquelle le test $\psi_{0.1} = 0$
$$\mathbb{P}(H_{0} | \psi_{0.1}=0) = \frac{(1-\alpha(0.1))\mathbb{P}(H_0) }{ (1-\alpha(0.1))\mathbb{P}(H_{0}) + \beta(0.1) \mathbb{P}(H_{1}) } \sim 0.9877 \ldots (16)$$
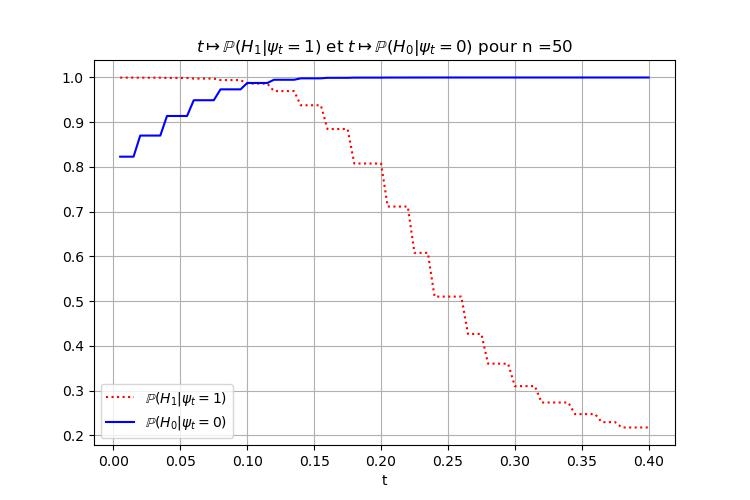
On pourrait même se demander comment se comporte notre test en fonction de $t$. C'est ce qu'illustre la Figure 2. Pour $n=50$ fixé il y a une région "optimale" dans laquelle nous pouvons faire confiance au test avec une forte probabilité (supérieure à $0.95$, par exemple) d'avoir raison. Autour de cette zone ($t \in \left[ 0.1, 0.125\right]$ à peu près), le test est très fiable dans les deux sens : si $\psi = 1$ on peut considérer que la pièce est truquée ; et si $\psi =0$ on peut considérer qu'elle est équilibrée sans trop risquer de se tromper. Pour toutes ces valeurs notre test semble raisonnablement précis.
Exemple Contre-Intuitif - Paradoxe des évènements rares
En s'appuyant sur les notions de la section précédente, nous pouvons maintenant présenter un exemple plus réaliste, qui s'explique encore très bien par analogie avec nos lancers de pièces.
Supposons qu'un test de grossesse (notée $\psi$ également) a une erreur de première espèce de $0.01$ ($1%$) et une erreur de seconde espèce de $0.01$ ($1%$). Dans ce cas, $H_1$ correspond au fait d'être enceinte, et $H_0$ à ne pas l'être. Supposons que le pourcentage de la population enceinte est $1%$. Vous faites le test (par pure curiosité) et il est positif !?! Avant de paniquer (ou de vous réjouir !) vous décidez de faire un autre petit calcul (en fait déjà mené plus haut) :
$$\mathbb{P}(H_1 | \psi = 1) = \frac{(1-\beta)0.01}{\mathbb{P}(\psi=1|H_0)\mathbb{P}(H_0) + \mathbb{P}(\psi=1|H_1)\mathbb{P}(H_1)}$$ $$= \frac{(1-0.01)\times 0.01}{0.01\times 0.99 + (1- 0.01)\times 0.01}$$ $$= 0.5$$
Autrement dit, la probabilité d'être enceinte ($H_{1}$) sachant que le test est positif, n'est que de $0.5$ ! Ainsi, il vaut vraiment la peine de refaire un test pour être sûr(e).
Comment comprendre ce résultat ? Si par exemple il y a 9900 personnes non enceintes et 100 personnes enceintes, et que nous appliquons le test à toutes, alors nous nous attendons à avoir à peu près $0.01 \times 9900 = 99$ des personnes non enceintes avec un test positif (faux positif, ou erreur de première espèce). De même, nous nous attendons avoir $0.99 \times 100 = 99$, soit le même nombre, de personnes enceintes avec un résultat positif. De tous les résultats positifs, la moitié sont donc des faux !
En interprétant cela en termes de lancers de pièces, on voit que la qualité du test dépend du phénomène que nous mesurons. C'est ainsi que si dans votre sac à main vous aviez eu $1000$ pièces d'un euro (et non $4$ comme dans la section précédente), la qualité de notre test aurait été différente. On peut le voir sur la Figure 3 qui montre l'effet d'avoir 999 pièces régulières d'un euro dans le sac.

En fait, si maintenant vous prenez $t = 0.1$, et que votre test identifie une pièce comme truquée, alors vous avez une probabilité de $0.2$ (environ) d'avoir raison si vous acceptez ce que votre test vous indique.

Inversement, supposons maintenant que vous êtes le propriétaire de la boutique de magie qui vend les pièces truquées. Vous placez (par erreur) une pièce équilibrée d'un euro dans un sac contenant $999$ pièces truquées et vous voulez l'identifier avec ce même test. La qualité du test sera alors plutôt décrite par le graphe dans la Figure 4.
Solution du paradoxe
Si nous reprenons l'exemple du test de grossesse il semble donc que celui-ci n'est pas assez bon pour lui faire confiance. Si, quand le test est positif, vous n'avez qu'une chance sur deux d'être vraiment enceinte, autant jouer le résultat à pile ou face !? Que faire alors pour en avoir le cœur net ? Il y a essentiellement deux méthodes. Le premier choix, et le plus naturel, est de faire un test plus précis. Et bien sûr, pour confirmer une grossesse on fait généralement suivre le premier test par une prise de sang. Mais une autre méthode fonctionnerait également. Elle consisterait à réitérer (plusieurs fois) le premier test de grossesse "grossier". Supposons en effet que vous répétiez deux fois ce test et que les résultats que vous obtenez sont indépendants (c'est une hypothèse). Notons $\psi$ et $\overline{\psi}$ ces deux tests ; alors
$$\mathbb{P}(H_1 | {\psi = 1}\cap{\overline{\psi}=1}) = \frac{\mathbb{P}\left({\psi=1}\cap{\overline{\psi}=1} | H_{1}\right) \mathbb{P}\left(H_{1}\right)}{\mathbb{P}\left({\psi=1}\cap{\overline{\psi}=1}\right)}$$ $$= \frac{\mathbb{P}\left(\psi=1|H_{1}\right)\mathbb{P}\left(\overline{\psi}=1|H_{1}\right)\mathbb{P}\left(H_{1}\right)}{\mathbb{P}({\psi=1}\cap{\overline{\psi}=1}|H_0)\mathbb{P}(H_0) + \mathbb{P}({\psi=1}\cap{\overline{\psi}=1}|H_1)\mathbb{P}(H_1)}$$ $$= \frac{\mathbb{P}\left(\psi=1|H_{1}\right)\mathbb{P}\left(\overline{\psi}=1|H_{1}\right)\mathbb{P}\left(H_{1}\right)}{\mathbb{P}\left(\psi=1|H_{0}\right)\mathbb{P}\left(\overline{\psi}=1|H_0\right)\mathbb{P}(H_0) + \mathbb{P}\left(\psi=1|H_{1}\right)\mathbb{P}\left(\overline{\psi}=1|H_1\right)\mathbb{P}(H_1)}$$ $$= \frac{(1-\beta)^{2}0.01}{\alpha^{2}0.99 + (1 - \beta)^{2}0.01} = 0.99.$$
En refaisant trois tests, la probabilité monterait à $0.9998979\ldots$. En pratique, on peut atteindre avec peu de tests n'importe quel niveau de fiabilité. Insistons néanmoins sur le fait que ce résultat n'est vrai que sous l'hypothèse d'indépendance, qui mérite d'être établie.
Conclusion
Cette petite introduction aux tests d'hypothèse montre certaines des subtilités que nous pouvons rencontrer dans le domaine des statistiques. Il y en aurait bien d'autres à explorer ! Nous pourrions par exemple nous demander comment les résultats vus pour la pièce truquée varient en fonction de la distribution de Bernoulli associée à la pièce truquée ($Ber(p)$ pour d'autres $p \neq 0.8$). Une autre question intéressante serait d'optimiser les paramètres $t$ du test pour atteindre les valeurs $\mathbb{P}\left(H_{1}|\psi=1\right)$ et $\mathbb{P}\left(H_{0}|\psi=0\right)$ souhaitées, avec un minimum de lancers $n$ (faire 50 lancers n'est pas très passionnant...). Et bien sûr, au-delà de tous lancers de pièces, ces outils s'appliquent à des situations plus complexes, aux enjeux bien plus forts.