PAR ma foi ! il y a plus de quarante ans que je fais des probabilités sans que j'en susse rien, et je vous suis le plus obligé du monde de m'avoir appris cela.
Une nécessité de clarification en probabilité
Si l’on fait généralement naître la notion de Probabilité avec Pascal (il s’agit en fait du premier raisonnement mettant en scène la notion de probabilité conditionnelle), cette branche des mathématiques n’en était pas encore devenue complètement une, encore même au début du XXe siècle. Et ceci alors que des utilisations de plus en plus fondamentales de ce concept ont cours en physique à cette époque1.
De la même façon qu’avant l’axiomatisation faite par Euclide on faisait tout de même de la géométrie, avant l’axiomatisation de la notion de probabilité par Kolmogorov en 1933, on utilisait la notion de probabilité, mais avec certaines réserves parfois, comme celles émises par exemple par Poincaré dans La Science et l’Hypothèse (2, chapitre 11) :
La conclusion qui semble résulter de tout cela, c'est que le calcul des probabilités est une science vaine, qu'il faut se défier de cet instinct obscur que nous nommions bon sens et auquel nous demandions de légitimer nos conventions.
Notons cependant que si Poincaré avait des réserves concernant les probabilités, cela ne veut pas dire qu’il y était fermé pour autant. On peut retenir en particulier l’usage qu’il en fit pour souligner le caractère non conclusif du système Bertillon dans le cadre de l’affaire Dreyfus1 (jouant ainsi d’une certaine façon un rôle dans la réhabilitation de ce dernier) ou encore son implication dans la thèse de Louis Bachelier2 3 (lequel avait suivi son cours de probabilité à la Sorbonne), thèse dont Poincaré a écrit le rapport et dont il était sans doute à l’époque l’un des rares à pouvoir en apprécier l’intérêt, le sujet étant alors non conventionnel4 (5 6 7).
Tout en reconnaissant en effet leur importance dans les sciences en général, Poincaré critique la définition même de la notion de probabilité, en montrant, sur un exemple, que cela revient à définir « le probable par le probable ». En effet, la définition classique basée sur le quotient du nombre de cas possibles sur le nombre de cas total, utilise de manière implicite la notion d’équiprobabilité, puisque tous les cas possibles doivent alors être également probables entre eux, autrement dit, équiprobables. Par conséquent, il faudrait poser derrière chaque utilisation de cette définition une convention (qui dépendrait alors du bon sens), de manière à lui donner l’assise lui faisant initialement défaut.
Poincaré continue son raisonnement en montrant que même ainsi, une convention claire ne suffit pas comme il l’illustre en évoquant le paradoxe de Bertrand où différentes conventions toutes aussi raisonnables mathématiquement l’une que l’autre fournissent trois résultats différents.
Le paradoxe de Bertrand
Pour appliquer la formule intuitive \(\frac{\text{nombre de cas favorables}}{\text{nombre de cas possibles}}\), il faut pouvoir caractériser ce que l’on entend par cas (mathématiquement parlant) vis-à-vis du problème donné : autrement dit, comment le caractériser de manière à pouvoir dénombrer, quantifier, les différentes situations possibles.
On rappelle à cet effet, sans démonstration, les faits suivants (dans toute la suite, \(O\) désigne le centre du cercle unité considéré dans l’énoncé) :
- un triangle équilatéral a tous ses angles égaux à \(\frac{\pi}{3}\) ;
- un triangle équilatéral inscrit dans un cercle de rayon \(1\) a pour longueur de côté \(\sqrt{3}\) ;
- se donner une corde revient à se donner son milieu \(m\) (la droite \((Om)\) est alors perpendiculaire à la corde elle-même).
Première méthode
Observons une corde qui serait le côté d’un triangle équilatéral ; son milieu \(m\) est alors à une distance \(\frac{1}{2}\) du centre \(O\). Intuitivement, si la distance de \(m\) au centre \(O\) est plus courte, la corde sera plus longue, et inversement. Il y a en effet une équivalence (la preuve est une conséquence facile du théorème de Pythagore) : la corde possède une longueur supérieure à \(\sqrt{3}\) si et seulement si la distance de son milieu \(m\) au centre \(O\) est inférieure à \(\frac{1}{2}\).
Autrement dit, toutes les cordes qui nous intéressent sont celles dont le centre \(m\) se trouve à l’intérieur du cercle de centre \(O\) et de rayon \(\frac{1}{2}\). On peut alors mesurer les cas favorables par l'aire de ce disque. En effet, l’ensemble des cordes quelconques correspond à l’ensemble des milieux qui peuvent alors être n’importe quel point à l’intérieur du cercle unité), d’où la probabilité : \[\frac{ \text{aire du disque de rayon $\frac{1}{2}$}}{\text{aire du disque unité}} = \frac{ \pi\times(\frac{1}{2})^2 }{\pi\times 1^2} = \frac{1}{4}.\]
La probabilité est \(\frac{1}{4}\).
Deuxième méthode
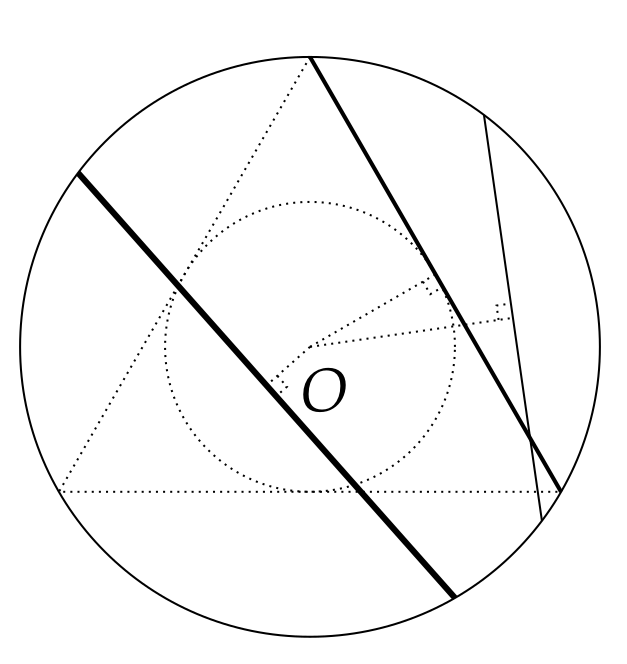
On choisit au hasard les extrémités de la corde, soit deux points sur le cercle. Le choix du premier n’a pas d’incidence, compte tenu de la symétrie du problème, vis-à-vis de notre condition ; celui-ci fixé, traçons la tangente \(T\) en ce point. Lorsque nous choisissons le deuxième point, la corde qui en résulte fait un angle avec \(T\) compris entre \(0\) et \(\pi\) (appartenant donc à l’intervalle \(]0,\pi[\)). Cet angle va constituer le paramètre qui nous permettra de caractériser quantitativement les cas favorables. Traçons un triangle équilatéral dont l’un des sommets est le premier point fixé :

Si l’angle en question est compris entre \(\frac{\pi}{3}\) et \(\frac{2\pi}{3}\) la corde est plus grande que le côté du triangle équilatéral, sinon elle est plus petite. Les cas favorables correspondent ainsi à un angle compris entre \(\frac{\pi}{3}\) et \(\frac{2\pi}{3}\), ce qui nous donne, (en se rappelant, que, sans condition de longueur de corde, l’angle évolue dans \(]0,\pi[\)) :
\[\frac{ \text{longueur de l'intervalle $[\frac{\pi}{3},\frac{2\pi}{3}]$}}{\text{longueur de l'intervalle $]0,\pi[$}} = \frac{ \frac{2\pi}{3}-\frac{\pi}{3}}{\pi-0} = \frac{1}{3}.\]
La probabilité est \(\frac{1}{3}\).
Troisième méthode
On choisit au hasard un rayon du cercle (à nouveau ce premier choix n’a pas d’incidence, compte tenu de la symétrie du problème, vis-à-vis de notre condition). Celui-ci fixé, on choisit ensuite un point \(m\) sur ce rayon qui correspondra au milieu d’une corde. On se retrouve dans une discussion proche de celle de la première méthode : si \(m\) est à une distance \(\frac{1}{2}\) du centre \(O\), la longueur de la corde est de \(\sqrt{3}\), si cette distance est plus petite, la longueur de la corde est plus grande, et inversement, comme on peut le voir sur la figure suivante.
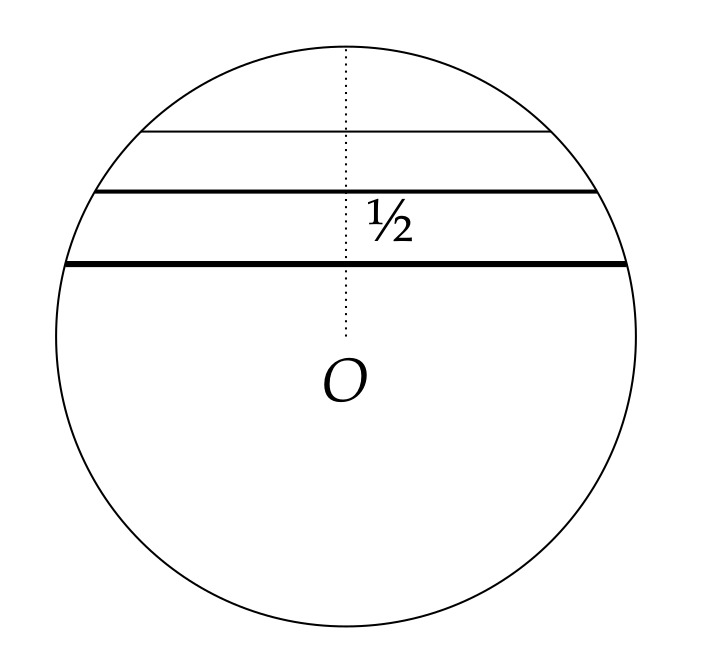
Le nombre de cas favorables correspond au cas où la distance entre \(O\) et \(m\) varie entre \(0\) et \(\frac{1}{2}\) (sans condition particulière, elle varie entre \(0\) et \(1\), le cercle étant de rayon \(1\)), d’où : \[\frac{ \text{longueur de l'intervalle $[0,\frac{1}{2}]$}}{\text{longueur de l'intervalle $[0,1[$}} = \frac{\frac{1}{2}-0}{1-0} = \frac{1}{2}.\]
La probabilité est \(\frac{1}{2}\).
Commentaire du raisonnement de Poincaré
À la lumière des progrès effectués par la théorie des probabilités depuis cette époque, nous allons pouvoir examiner de plus près les deux objections de Poincaré.
Premièrement, la critique de Poincaré 1 contre la définition classique des probabilités2 est non seulement très fine (puisqu’il a mis exactement en relief le cercle vicieux de l’utilisation implicite de la notion d’équiprobabilité), mais l’insatisfaction qu’il en retire est d’autant plus clairvoyante que cette définition fut, après l’axiomatique de Kolmogorov3, complètement abandonnée.
En ce qui concerne la deuxième objection, nous allons montrer que le paradoxe de Bertrand n’a pas de sens en lui-même, et qu’il repose sur une illusion. Il en possède pourtant un pour Poincaré 1°) du fait de la nécessité de poser une convention pour chaque problème utilisant les probabilités (encore une fois par insuffisance de la définition) 2°) que le problème posé est typique de ce que l’on peut attendre des probabilités, à savoir une application sur un problème scientifique concret4. De ce point de vue, le paradoxe épouse donc très logiquement le raisonnement global.
On pourrait avoir la tentation de se débarrasser de ce paradoxe en utilisant le point de vue moderne et en argumentant que, de toute manière, la question ne se pose plus, puisqu’une fois la probabilité bien définie, nul besoin de faire encore appel à une convention au sens où l’entend Poincaré (proche de l’emploi courant de la notion d’axiome, c’est-à-dire débarrassé de toutes connotations ontologiques), sorte de mini-axiomatique mouvante au secours d’une définition incomplète. Et avoir également la tentation d'aller plus loin et de voir dans le paradoxe de Bertrand lui-même, un des exemples de la faillite de cette antique définition qui amène à faire des conventions dénuées de sens (bien que d’apparence raisonnable) puisqu’impliquant justement des résultats différents.
Cette dernière facilité, au mieux improductive et au pire dangereuse, comme toutes les facilités, n’en est pas plus satisfaisante pour autant : quand bien même la notion de probabilité serait définie très clairement, on ne peut se soustraire au choix d’un modèle lors de la phase d’application de cette notion (à la façon du choix d’un repère, des symétries, etc. dans un modèle physique). Aussi, le problème du paradoxe de Bertrand n’est pas tant d’avoir choisi un modèle (ou une convention) plus ou moins raisonnable qu’un autre, le vrai problème logique est que chacune de ces conventions ne correspond, en fait, pas à la même situation ! Pour faire une analogie, cela reviendrait à calculer la probabilité qu’un astéroïde percute la terre
- dans un monde vérifiant les lois de Newton ;
- dans un monde vérifiant des lois différentes.
Tout le paradoxe repose uniquement sur la phrase suivante, phrase qui semble suffisamment claire à l’intellect et dans le même temps suffisamment floue pour engendrer une indétermination mathématique : tracer au hasard une corde. Tout dépend de la méthode employée, et peu importe le caractère intrinsèquement raisonnable de celle-ci, chacune d’entre elles correspondant à une loi de probabilité différente5.
Pour mieux percevoir le mécanisme sous-jacent voici un exemple d’une question strictement analogue d’un point de vue logique :
- Supposons que l'on tire au hasard un nombre (entier) entre \(2\) et \(12\), quelle est la probabilité qu’il soit plus petit que \(4\) ?
Le tableau ci-dessous montre la correspondance logique entre ce problème et celui du paradoxe de Bertrand :
| Paradoxe de Bertrand | Notre question | |
|---|---|---|
| Univers des possibles | une région (disque délimité par un cercle) dans l’ensemble des points du plan | une région (nombres de \(2\) à \(12\)) dans l’ensemble des entiers |
| Élément considéré | une corde | un entier |
| Condition | l’élément doit appartenir à une sous-région (tous les points le constituant doivent se trouver entre le cercle principal et le cercle de même centre et de demi-rayon) | l’élément doit appartenir à une sous-région (l’ensemble \(\{2,3,4\}\)) |
| Méthode de tirage au sort de l’élément | non précisée | non précisée |
De la même façon, selon la méthode employée pour tirer un nombre au hasard, les réponses seront différentes ; voici quelques exemples de méthodes raisonnables :
-
tirer un dé à \(11\) faces numérotées de \(2\) à \(12\) (ou encore tirer au hasard dans une urne des boules numérotées de \(2\) à \(12\)) ;
-
tirer simultanément deux dés à \(6\) faces et additionner les résultats ;
-
partir de \(2\) (fortune initiale du joueur), tirer \(10\) fois à pile ou face une pièce de monnaie et ajouter \(1\) à chaque fois que pile est obtenu.
Cela n’a a priori rien de choquant de trouver des résultats différents puisqu’en réalité la loi de probabilité sous-jacente est différente6.
Notons que, a contrario, on peut donner un exemple de deux modélisations différentes (i.e. deux espaces différents munis chacun d’une probabilité différente). Pour reprendre le vocabulaire de Poincaré sur la problématique des différents types de géométries, l’une des deux est peut-être plus commode, plus intuitive que l’autre, mais aucune des deux n’est plus vraie que l’autre.
Autrement dit, de la même façon qu’en géométrie, une fois l’axiomatique posée, nul besoin de bon sens pour fixer des conventions mathématiques ; il n’en demeure cependant pas moins, encore une fois à l’instar de la géométrie, que la question du choix de l’axiomatique se pose alors à son tour.
Le choix du modèle (décision de prendre sur l’espace étudié une probabilité plutôt qu’une autre) n’est plus une question mathématique, mais devient un choix dépendant de l’application voulue, exactement de la même manière que l’on décidera par exemple d’utiliser plutôt la géométrie sphérique que la géométrie euclidienne dans une certaine situation donnée.
Définition axiomatique des probabilités
Comme nous l’avons esquissé précédemment, les probabilités firent leur entrée dans le monde des mathématiques en tant que discipline à part entière lors de l’axiomatisation développée par Kolmogorov7 en 1933 8 (ce qui n’exclut pas qu’il y avait eu déjà, depuis le XVIII siècle jusqu’à cette date, des résultats et réflexions préalables sur un certain nombre de sujets très importants).
Notons que cette approche a pu se développer grâce, en partie, aux nouveaux outils d’analyse proposés par Lebesgue et Borel, au début des années 1900, pour définir l’intégration : la théorie de la mesure.
Montrons dans un premier temps de quelle manière la généralisation de la notion de probabilité est liée à la théorie de la mesure (et c’est dans cette généralisation que réside le germe de l’axiomatisation : il est assez frappant de constater que dans la version restreinte de la théorie classique des probabilités, la vision qu’elle proposait n’était finalement peut-être pas suffisamment globale pour en tirer une structure satisfaisante ; un peu comme une géométrie où l’on n’aurait considéré que des segments et jamais des droites).
En probabilité, jusqu’au XIX siècle, on pouvait considérer des problèmes sur des ensembles discrets, éventuellement dénombrables (pouvant être mis en correspondance avec \(\mathbb{N}\)), ou dans certains cas particuliers mettant en rapport des quantités commensurables : par exemple, si l’on se pose la question de la probabilité de tirer au hasard un nombre plus petit que \(\frac{1}{3}\) dans l’intervalle \([0,1]\), bien que l’on raisonne sur des ensembles infinis non-dénombrables9 leurs rapports sont comparables ; intuitivement cela revient à calculer \(\frac{\text{longueur}([0,\frac{1}{3}])}{\text{longueur}([0,1])}=\frac{ \frac{1}{3}}{1}=\frac{1}{3}.\)
Mais, quand bien même l’on se satisfasse de l’intuition de la formule précédente, comment faire, par exemple, pour calculer la probabilité de tirer un nombre rationnel dans l’intervalle \([0,1]\) ? Il faut pouvoir au moins mesurer l’ensemble des rationnels dans l’intervalle \([0,1]\). La théorie de la mesure de Borel-Lebesgue permet de répondre à ces questions de mesurabilités10.
La première étape est de déterminer quels ensembles sont mesurables. La théorie de la mesure11 permet de définir une classe de sous-ensembles (les boréliens) dotés d’une structure particulière (dite de tribu) sur laquelle on peut définir une mesure qui prolonge la mesure intuitive que l’on peut faire des segments de la droite réelle (c’est-à-dire si \([a,b]\) est un segment, sa mesure est \(b-a\)). On peut se sentir peut-être un peu frustré de ne pas pouvoir mesurer n’importe quel sous-ensemble de \(\mathbb{R}\), cependant, il faut remarquer que la classe des boréliens est si vaste, que pour construire un ensemble non-mesurable il faut passer par l’axiome du choix : il n’est pas possible de construire un ensemble non-mesurable en un nombre fini d’opérations…
Nous en sommes arrivés à la première brique permettant de définir la notion de probabilité : la définition d’un espace mesurable.
Définition
—Espace mesurable—Soit \(\Omega\) un espace quelconque et \(\mathcal{A}\) un ensemble d’éléments de \(\mathcal{P}(\Omega)\) (ensemble des parties de \(\Omega\) ; \(\mathcal{A}\) est donc un ensemble de sous-ensembles de \(\Omega\)). Si \(\mathcal{A}\) vérifie les conditions suivantes (\(\mathcal{A}\) est alors appelé une tribu) :
- l’espace entier appartient à \(\mathcal{A}\) : \(\Omega\in \mathcal{A}\) ;
- si \(B\) appartient à \(\mathcal{A}\), son complémentaire (l’ensemble \(\Omega\) privé des éléments de \(B\)), noté \({}^c\!B\), aussi : \(B \in \mathcal{A}\ \ \Rightarrow \ \ {}^c\!B \in \mathcal{A}\) ;
- une réunion dénombrable d’éléments de \(\mathcal{A}\) est encore un élément de \(\mathcal{A}\),
on dit que \(\Omega\) est un espace mesurable (on le note en général \((\Omega,\mathcal{A})\), pour rappeler la tribu \(\mathcal{A}\) qui lui donne cette structure particulière).
La théorie de la mesure s’étant développée initialement indépendamment des probabilités, certains éléments communs possèdent des dénominations différentes ; en théorie des probabilités, un espace mesurable correspond à l’univers des possibles (pour une expérience donnée) ; les éléments de la tribu \(\mathcal{A}\) sont appelés des événements (le complémentaire d’un événement \(B\) est alors appelé l’événement contraire), ce qui donne une idée peut-être plus intuitive des motivations de ce formalisme.
Sur un espace mesurable on peut alors enfin définir une probabilité :
Définition
—Probabilité—Soit \((\Omega,\mathcal{A})\) un espace mesurable. L’application \(\mathbb{P}\) qui à tout élément de \(\mathcal{A}\) associe un nombre compris entre \(0\) et \(1\) est une probabilité si et seulement si elle vérifie les propriétés suivantes (définition axiomatique) :
- \(\mathbb{P}(\Omega)=1\) (ce qui correspond à l’intuition que la probabilité de tout ce qui est possible est égale à \(1\)) ;
- pour toute collection d’événements disjoints deux à deux1 \(A_1, A_2,\dots, A_n,\dots\) on a2 : \[\mathbb{P}(A_1\cup A_2 \cup\cdots \cup A_n \cup \cdots)=\mathbb{P}(A_1)+\mathbb{P}(A_2)+\cdots+\mathbb{P}(A_n)+\cdots{},\] ce qui correspond à l’intuition que la probabilité d’événements a priori incompatibles entre eux est égale à la somme de la probabilité de chaque événement pris séparément.
Ce formalisme permet non seulement de s’abstraire du court-circuit logique que Poincaré mettait en exergue dans la définition classique des probabilités, mais de pouvoir encore s’appliquer à des ensembles nettement plus compliqués où l’on ne peut plus se contenter de faire du dénombrement (et où parfois celui-ci n’a plus de sens).
La définition classique ne correspond plus qu’à un cas particulier très restreint : la probabilité uniforme sur un ensemble fini. En particulier, toutes les propriétés ayant été démontrées dans ce cas particulier sont donc encore vraies.
Plusieurs façon d’aborder un même problème
Pour conclure, donnons un exemple qui illustrera à la fois le formalisme moderne dans un cas particulier simple et montrera dans le même temps que l’on peut formaliser le même problème de manière radicalement différente (avec deux probabilités distinctes !) et obtenir cependant le résultat correct : aucune des deux n’est cependant plus vraie l’une que l’autre, pour reprendre l’expression de Poincaré à propos des géométries euclidienne et non-euclidiennes !
On se pose la question suivante :
Si on lance deux dés, quelle est la probabilité d’obtenir \(k\) fois (\(k=0\), \(1\) ou \(2\)) un \(6\) ?
Modélisation 1 :
On choisit d’abord un espace \(\Omega\), qui sera ici l’ensemble des couples possibles formés à partir d’entiers compris entre \(1\) et \(6\) soit1 : \[\Omega =\{ (\omega_1,\omega_2), \ \omega_1\in \{1,\dots, 6\},\; \omega_1\in \{1,\dots, 6\} \} .\] Le choix de la tribu \(\mathcal{A}\) (ensemble des événements considérés), dans le cas discret est trivial (mais non nécessairement unique ; il repose encore sur un choix), il suffit généralement de prendre l’ensemble des parties de \(\Omega\) (ce qui ne sera plus vrai dans un cas plus général, puisque l’on avait dit que l’on ne pouvait plus alors toujours définir la probabilité d’une partie quelconque de \(\Omega\)).
Enfin, on choisit de munir cet espace de la probabilité uniforme, autrement dit, la probabilité qui pour n’importe quel singleton de \(\Omega\) vaut \[\frac{1}{|\Omega|},\] où \(|\Omega|\) désigne le nombre d’éléments de \(\Omega\) (ici il y a \(6\times 6\) couples possibles, soit \(|\Omega|=36\)).
On remarque que, par la deuxième propriété, on peut alors calculer la probabilité d’une partie quelconque \(A\) de \(\Omega\) : \(A\) étant réunion disjointe de ses propres éléments, la probabilité de \(A\) est égale à la somme des probabilités de tous ses points : \[\mathbb{P}(A)= \sum_{a\in A}\mathbb{P}(a)= \sum_{a\in A} \frac{1}{|\Omega|}= \frac{|A|}{|\Omega|},\] et l’on retrouve la formule intuitive du nombre de cas favorables (\(|A|\) : nombre d’éléments de l’événement \(A\)) sur le nombre de cas total (nombre d’éléments de \(\Omega\)).
Il ne nous reste plus qu’a caractériser les événements qui nous intéressent :
- l’événement tirer \(2\) fois \(6\) (i.e. \(k=2\)) correspond à l’ensemble contenant le seul couple possible dans ce cas de figure : \(A_2=\{ (6,6) \}\). Puisque \(A_2\) possède un seul élément, on a \(|A_2|=1\) ;
- l’événement tirer (exactement) \(1\) fois \(6\) (i.e. \(k=1\)) correspond à tous les couples possédant exactement un \(6\) : \((6,1)\), \((1,6)\), \((6,2)\), \((2,6)\),…, \((6,5)\), \((5,6)\), soit à l’ensemble \[A_1= \{ (6,k),\ k \in \{1,\dots, 5\} \}\cup \{ (k,6),\ k \in \{1,\dots, 5\} \}.\] On compte sans difficulté qu’il y a \(10\) couples possédant cette caractéristique, soit \(|A_1|=10\) ;
- l’événement tirer \(0\) fois \(6\) (i.e. \(k=0\)) correspond à tous les autres couples : si on nomme l’ensemble de ceux-ci \(A_0\), sans décrire tous les éléments de \(A_0\), on peut calculer quand même le nombre d’éléments qu’il contient : il s’agit du nombre de couples total (\(|\Omega|\)) auquel on soustrait le nombre d’éléments de \(A_2\) et de \(A_1\), soit \(36-1-10=25\) et ainsi \(|A_0|=25\).
On en déduit que la probabilité de tirer deux fois six est de \(\frac{1}{36}\), celle de tirer une fois six de \(\frac{5}{18}\), et enfin, celle de n’en tirer aucun est de \(\frac{25}{36}\) (soit \(70\%\) de chance environ).
Modélisation 2 :
On pourrait choisir de prendre comme univers \(\Omega\) l’ensemble \(\{0,1,2 \}\) correspondant directement au nombre d’occurence du chiffre six. Un argument combinatoire très classique nous permet de définir, dans ce cas, la probabilité sur cet ensemble par2 : pour tout \(i\in \{0,1,2 \}\), \[\mathbb{P}(i)= \binom{2}{i}\Big(\frac{1}{6} \Big)^i\Big(\frac{5}{6} \Big)^{2-i}.\] On retrouve alors les même résultats que précédemment.
Notons enfin que si cette dernière modélisation peut sembler de prime abord plus artificielle, elle est cependant, une fois sa validité établie, beaucoup plus pratique puisqu’immédiatemment généralisable à un nombre quelconque de lancé de dé : si on lance \(n\) fois un dé, la probabilité d’obtenir \(p\) fois un six est simplement \[\mathbb{P}(p)= \binom{n}{p}\Big(\frac{1}{6} \Big)^p\Big(\frac{5}{6} \Big)^{n-p}.\] Il est alors immédiat d’obtenir par exemple la probabilité d’obtenir (exactement) \(6\) fois un six après avoir lancé \(50\) fois un dé (l’application de la formule précédente fournit une réponse de \(11\%\) de chance), alors que l’on s’imagine sans peine que dénombrer cet ensemble de la même manière que dans le cas de la modélisation 1, prendrait un certain temps…